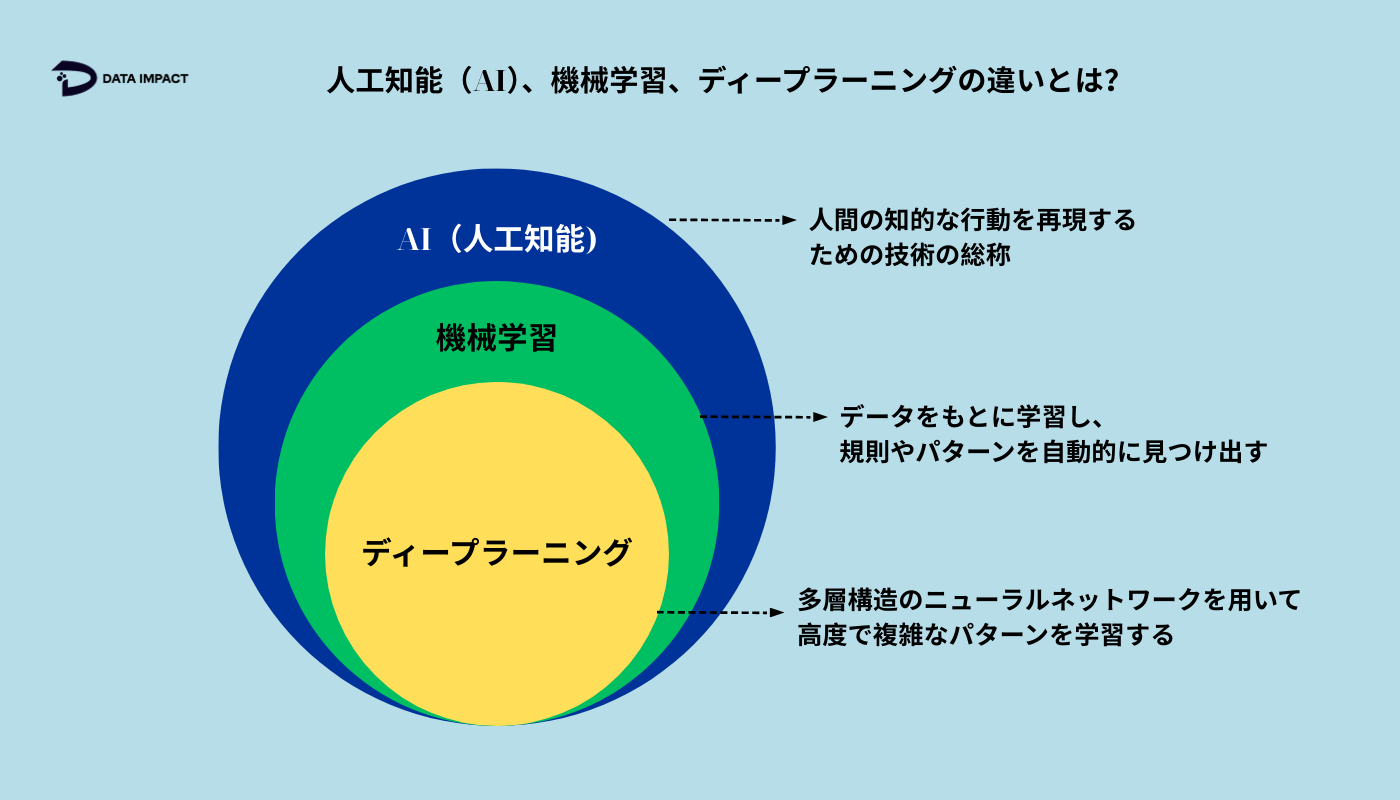
人工知能(AI)、機械学習、ディープラーニングの違いとは?
デジタルトランスフォーメーションの時代において、AI(人工知能)、機械学習、ディープラーニングといった用語は、企業の技術レポート、データ戦略、デジタルトランスフォーメーション計画においてますます頻繁に登場しています。しかし、これらの概念が頻繁に混同されることで、懸念される現実が生じています。多くの組織がAIに投資しているにもかかわらず、それに見合った価値を得られていないのです。
その理由は技術そのものではなく、誤解と誤った選択にあります。全ての問題に深層学習が必要なわけではありません。全ての企業が機械学習を導入できる状態にあるわけでもありません。そしてAIは、私たちが考えるほど常に「賢い」とは限りません。
Data Impactによる本記事では以下の点がわかります:
- AI、機械学習、深層学習の真の性質を理解します。
- これら3つの概念の違いを明確に区別します。
- データ分析やビジネス運営における適用方法を理解します。
I. 人工知能(AI)とは?

人工知能(AI)の定義
人工知能(AI)とは、人間の知能を部分的に模倣できるシステムの構築に焦点を当てた、コンピュータサイエンスの一分野です。
AIシステムは、以下の能力を有する場合に「知的」であると考えられます:
- 論理を参照し処理する能力
- 規則やデータに基づく意思決定
- 特定の状況における経験からの学習
- 自然言語の理解と処理
- 画像、音声、行動パターンの認識
特に強調すべき点は:AIは最も広範な概念であり、様々な手法、知能レベル、動作モードを包含しています。
実践におけるAIの例
AIは多くの身近な活動に存在しています:
- 自動化されたカスタマーサービスチャットボット
- ウェブサイトやアプリケーション上の商品推薦システム
- セキュリティや銀行業務における顔認証
- 自動運転車や高度運転支援システム
これらのシステムの共通点は、迅速な意思決定や大量情報の処理において、人間の代わりとなる、あるいは補助する役割を果たすことです。
AIは常にデータから学習するのでしょうか?
❌すべてのAIがデータから学習するわけではありません。
ビジネスで非常に一般的なAIのタイプはルールベースAIです。このシステムは:
- 事前にプログラムされた「“If – Then」というルールに従って動作します。
- 自己学習能力を持っていません。
- 変化する状況に適応できません。
シンプルではありますが、ルールベースAIは以下のような場面で依然として非常に効果的です:
- 安定したビジネスプロセスです。
- 明確な論理的問題です。
- 制御と説明の必要性が高い場面です。
II. 機械学習とは?

機械学習 – AIの一分野
機械学習とは、人工知能(AI)の一分野であり、システムが以下のことを可能にします:
- 過去のデータから学習します。
- 隠れたパターンを発見します。
- 予測を行ったり、新しいデータを分類したりします。
ルールベースのAIとは異なり、機械学習では人間が全てのルールを定義する必要はありません。代わりに、データからパターンを学習します。
機械学習の仕組み
ビジネスにおける機械学習のプロセスは、通常以下の段階を含みます:
- データの収集(売上、顧客、業務など)。
- データのクリーニングと正規化です。
- 機械学習モデルのトレーニングです。
- 精度の評価です。
- 新しいデータへのモデルの適用です。
機械学習は自動的に効果を発揮するものではなく、以下の要素に大きく依存します:
- データの品質です。
- 入力変数の選択方法です。
- ビジネス上の課題に対する理解の深さです。
機械学習の主な種類
- 教師あり学習:ラベル付きデータから学習し、予測や分類に用いられます。
- 教師なし学習:データ内の隠れた構造を自動的に発見します。
- 半教師あり学習:ラベル付きデータとラベルなしデータを組み合わせます。
- 強化学習:試行錯誤と報酬を通じて学習します。
データ分析における機械学習の応用例
機械学習は特に構造化データに適しています:
- 収益と需要の予測。
- 行動に基づく顧客セグメンテーション。
- 不正検知。
- ユーザージャーニー分析
III. ディープラーニングとは?

ディープラーニング – 機械学習の高度なレベル
ディープラーニングは、機械学習の高度な分野であり、多層人工ニューラルネットワークを用いてデータを処理します。
この多層構造により、モデルは以下のことが可能となります:
- 複数のレベルでデータを表現することを学習します。
- 非常に複雑な関係を処理します。
- 人間の脳が情報を処理する方法を部分的に模倣します。
ディープラーニングの核心的な違い
従来の機械学習とは異なり:
- ディープラーニングは特徴量を自動的に抽出します。
- 変数設計への人的依存を軽減します。
- 大規模かつ非構造化データに対して極めて効果的です。
ディープラーニングの卓越した応用分野
ディープラーニングは以下を支える基盤となります:
- 画像・動画認識
- 音声認識
- 自然言語処理(NLP)
- ビッグデータおよび非構造化データ分析
IV. 人工知能(AI)・機械学習・ディープラーニング(深層学習)の比較

人工知能(AI)、機械学習、ディープラーニングの間の混乱の多くは、それらの定義そのものから生じるのではなく、企業が実際にそれらをどのように適用するかによって生じます。実際、多くのAIプロジェクトが失敗するのは、技術が未熟だからではなく、目の前の問題に対して不適切なレベルの技術を選択したためです。
「どの技術が最も先進的か?」と問う代わりに、企業はこう問うべきです:
「現在の課題を妥当なコストで解決するのに十分なAIのレベルは何か?」
1. AI、機械学習、深層学習の性質と知能レベルに関する比較
まず、これら3つの概念は直接競合するものではなく、階層的な関係にあることを理解することが重要です:
- AIは一般的な概念であり、人間の知能を模倣できるあらゆるシステムを含みます。
- 機械学習は、データから学習できるAIです。
- ディープラーニングは高度な機械学習であり、大規模かつ複雑なデータから深く学習します。
これは以下のことを意味します:
- AIシステムは必ずしも機械学習を必要としません。
- 機械学習システムは必ずしもディープラーニングを必要としません。
レベルが高くなるほど知能は向上しますが、コスト、複雑性、リスクも増加します。
2. 実世界のビジネス課題の種類による比較
ルールベースAIで十分なケースとは?
ルールベースAIは、以下のような問題に適しています:
- 明確で安定したビジネスプロセスを有しています。
- 完全な「If-Then」ロジックを提供できます。
- 時間の経過による変動が少ないです。
実用例:
- 顧客のリクエストを自動的に分類します。
- 文書の状態を確認します。
- 固定された質問に答えるチャットボット。
このようなケースでは、機械学習や深層学習を使用しても付加価値は生じず、むしろシステムをより複雑にし、制御が困難になる可能性があります。
機械学習が最適な選択となるのはいつでしょうか?
機械学習は以下のような場合に効果的です:
- ビジネスに信頼性の高い履歴データが存在する場合です。
- ルールは存在するが、ルールで記述することが困難な場合です。
- 問題が予測、分類、最適化を必要とする場合です。
一般的な例:
- 収益と需要の予測です。
- 行動に基づく顧客セグメントです。
- リスクスコアリングです。
- 不正検知です。
ほとんどのビジネスにおいて、機械学習は効率性、コスト、制御性の間で最良の「バランス」を提供します。
深層学習が本当に必要なのはいつでしょうか?
ディープラーニングは、以下の場合にのみ検討すべきです:
- 非構造化データ(画像、動画、音声、テキスト)が大きな割合を占める場合です。
- 問題が非常に複雑な場合です。
- 十分なデータ、インフラ、人材が揃っている場合です。
典型的な例:
- カメラからの画像認識。
- 音声認識。
- 自然言語処理(NLP)。
- 製造現場におけるコンピュータビジョン。
- 非構造化データが関与しない問題の場合、深層学習は通常、適切な選択肢とは言えません。
3. データ要件に基づく比較 – 成功か失敗かを分ける決定的要因
データはAIの「燃料」ですが、AIの各レベルでは異なる量の燃料が必要です。
- ルールベースAI:
-
大規模なデータセットを必要としません。
-
ルールと業務プロセスに依存します。
-
- 機械学習:
-
構造化されたデータを適量必要とします。
-
最も重要なのは、クリーンで文脈的に関連性のあるデータです。
-
- ディープラーニング:
-
-
非常に大規模なデータセット(数十万から数百万サンプル)が必要です。
-
データ量が少ない場合 → モデルは過学習を起こしやすく → 結果が不十分になります。
-
よくある誤り:
データ量が少ない場合にディープラーニングを適用 → モデルは古いデータから「学習」するが、新しいデータを誤って予測します。
4. 技術インフラと導入コストに基づく比較
長期的な運用コストは、しばしば過小評価されがちな要素です。
機械学習:
- 通常のCPUで実行可能です。
- 既存システムへの導入が容易です。
- コストが合理的です。
- 導入時間が短いです。
深層学習:
- GPUまたは高性能なクラウドインフラが必要です。
- トレーニングと保守コストが高いです。
- 高度に専門化された技術チームが必要です。
多くの深層学習プロジェクトが失敗するのは、モデルに欠陥があるからではなく、企業がインフラとコストを維持できないためです。
5. 解釈可能性とリスク管理の観点からの比較
ビジネス環境において、重要な問いは単に:
「モデルは正確か?」
だけではなく、
「なぜモデルはこの判断を下したのか?」
- 機械学習:
-
比較的説明可能です。
-
金融、銀行業務、リスク管理に適しています。
-
- ディープラーニング:
-
-
説明が難しいです。
-
「ブラックボックス」のような性質を持ちます。
-
監査やコンプライアンスにおいて制御が困難です。
-
重要性を増すAIガバナンスとAI倫理の観点では、モデルの説明可能性は単なる技術的問題ではなく、戦略的要素となります。
6. 企業はどのような場合に深層学習を使用すべきでないか?
以下の場合にはディープラーニングを避けるべきです:
- データ量が十分でない、または安定していない場合です。
- 機械学習で解決可能な問題である場合です。
- 早期の価値創出のために迅速な導入が必要な場合です。
- システムの判断について明確な説明が求められる場合です。
ディープラーニングは出発点ではなく、企業がデータと機械学習を習得した後の高度な段階です。
V. Data ImpactはAIと機械学習をどのように活用しているのでしょうか?
現実には、AIを導入する際の最大の問題は技術そのものではなく、誤ったアプローチにあります。多くの企業はトレンドに追随してAIに投資しますが、問題点やデータを明確に定義できず、価値を生み出せないままテストが長期化してしまいます。
Data Impactでは、複雑な技術ではなくビジネス価値に焦点を当て、実用的かつ効果的な方法でAIと機械学習に取り組んでおります。
ビジネス課題から始める
Data Impactは常に以下の特定を最優先いたします:
- 解決すべきビジネス課題です。
- 最適化または自動化すべきプロセスです。
- 達成すべき測定可能な価値です。
このアプローチにより、まず技術を選択し後から実装を試みるという事態を回避できます。
データと導入準備状況の評価
AI導入前に、データインパクトは以下の点を評価します:
- 既存データのソースと品質です。
- データの規模と統合能力です。
- データと課題の適合度です。
これらを踏まえ、ルールベースAI、機械学習、深層学習のいずれを採用すべきかを判断します。
迅速な価値創出のため機械学習を優先
大半のプロジェクトにおいて、Data Impactはまず機械学習を導入し以下を実現します:
- 早期の結果創出です。
- コスト最適化です。
- 容易な導入・運用です。
一般的な応用例としては、予測分析、顧客セグメンテーション、異常検知などが挙げられます。
ディープラーニングは、真に必要な場合にのみ適用してください。
ディープラーニングが推奨されるのは、以下の条件が満たされる場合のみです:
- 問題は非構造化データに関わる場合です。
- 十分なデータとインフラが整備されている場合です。
- 投資コストを上回るメリットが得られる場合です。
AIを実用段階へ移行させることです。
Data Impactは実験モデル段階で終わらせず、以下の点に重点を置きます:
-
既存システムへのAI統合です。
-
チームによる活用と監視の支援です。
-
モデルが長期的な価値を生み出すことの保証です。
Data Impactの目標は、企業がデータとAIを習得するお手伝いをすることです。流行を追うのではなく、適切なタイミングで適切に技術を導入することにあります。